10x Genomics
Chromium Single Cell Gene Expression
Cell Ranger5.0, printed on 05/18/2025
Filtering and Reclustering Workflow
By default, a .cloupe gene expression dataset includes all barcodes called as cells by Cell Ranger's cell caller. The default clusters and projections in a .cloupe file are derived from this set of cells. However, it may be more useful to only analyze a subset of these cells. For example, it may be desirable to more precisely screen out possible cell multiplets, dead cells, or cells with low diversity. Alternatively, it may be preferable to focus on a particular type of cell, or even remove a particular cell type from an analysis. For these reasons, Loupe Browser 5.0 now provides an interactive filtering and reclustering workflow. In a few short steps, it is possible to identify cells of interest, and then compute a Louvain clustering and t-SNE projection over these cells.
Entering the Reclustering Workflow
To enter the reclustering workflow, select Categories Mode, and choose any category. A Recluster button will appear above the cluster names. Clicking the Recluster button will launch a separate window for the workflow.
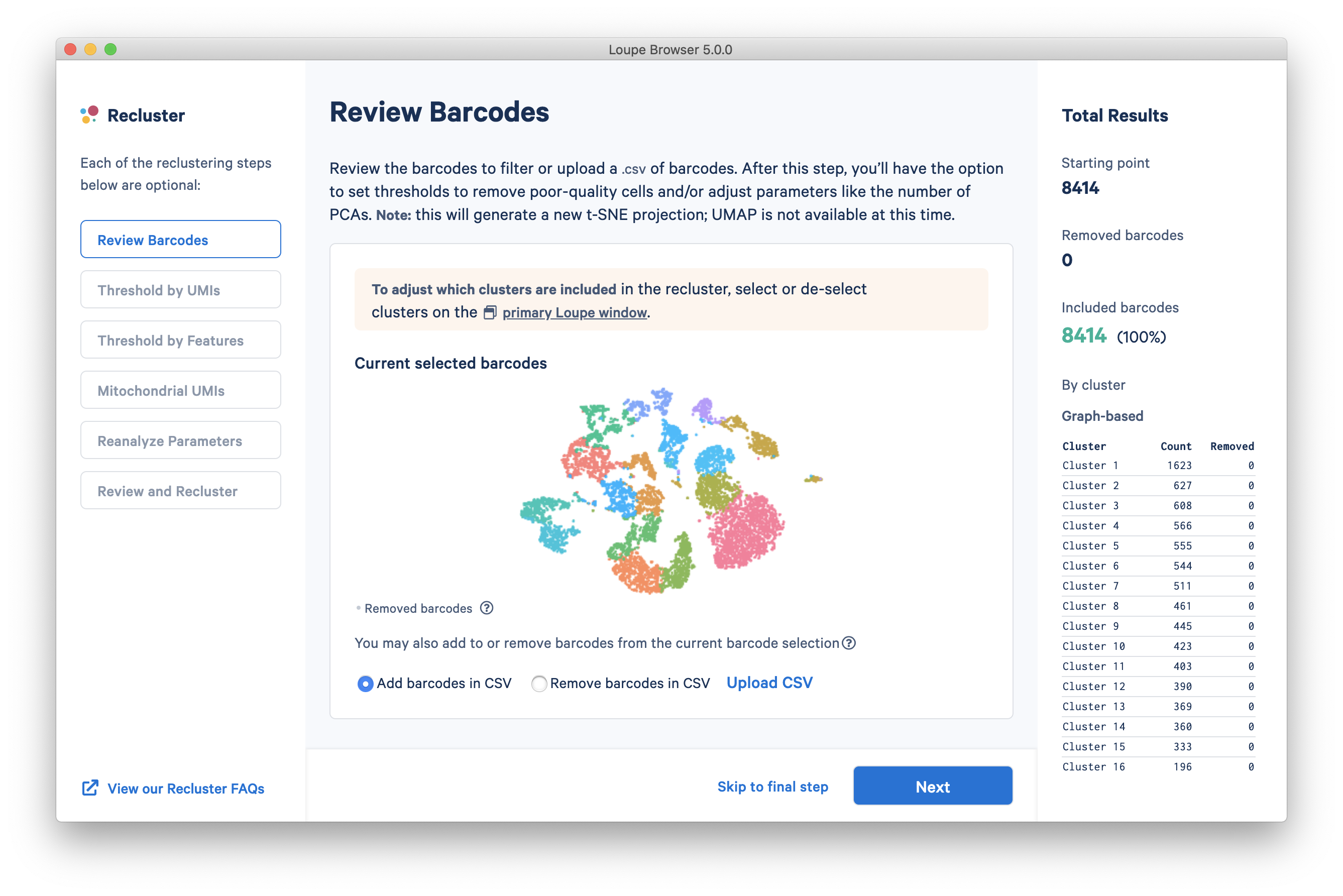
There are three columns for all steps in the workflow. The leftmost column shows the current progress through the workflow steps. It is possible to advance or go back to any step in the workflow at any time. The middle column contains the tooling for the active step. The rightmost column shows statistics about which barcodes have been removed. On the bottom of the reclustering window, there are buttons to advance to the next step, or go straight to the end.
Each step in the workflow merits additional explanation.
Review Barcodes
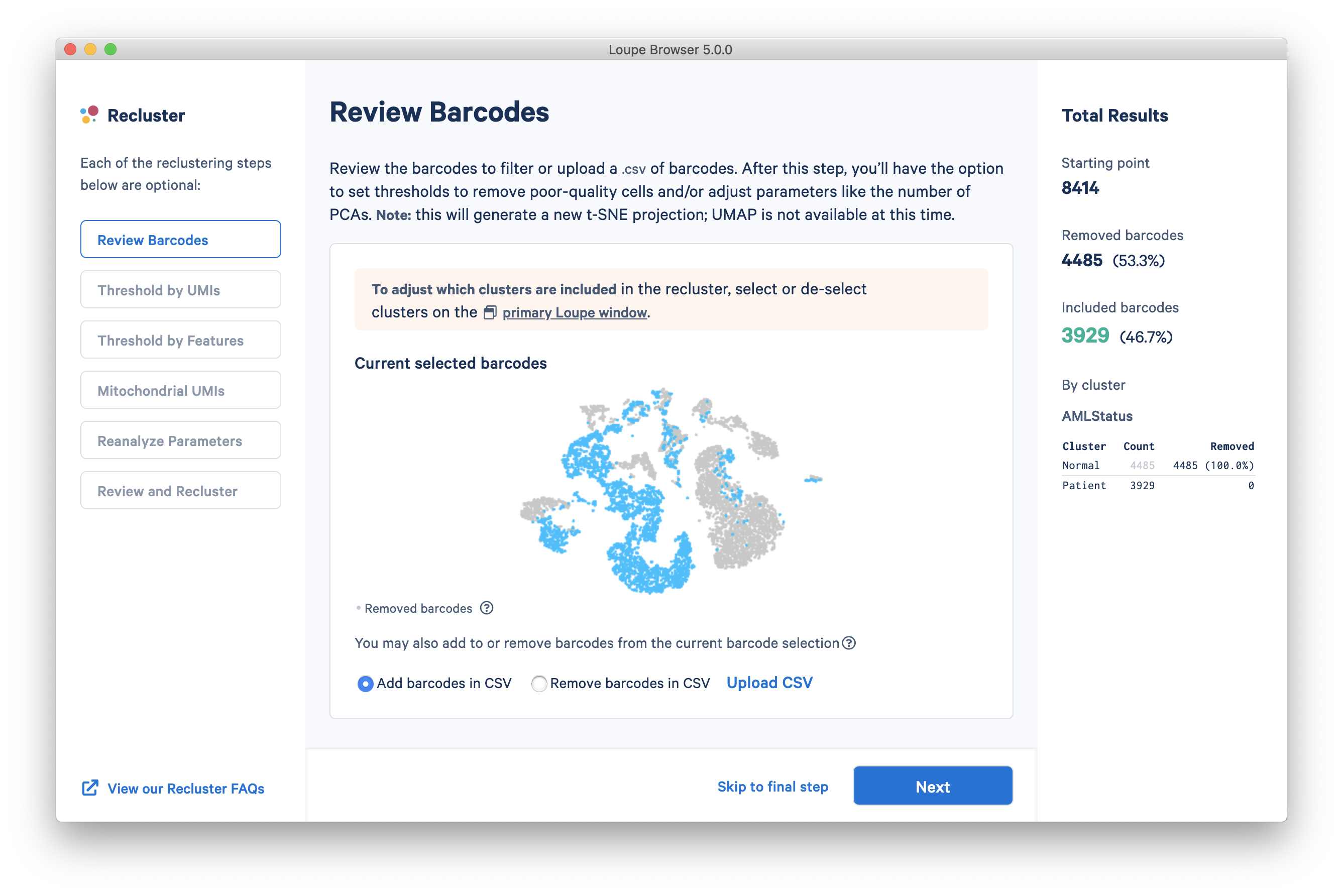
The first step, Review Barcodes, allows an initial filtering by either whole clusters, or a barcode list. It is connected to the main window; changing the category in the main window will change the active category in the reclustering workflow. By selecting or de-selecting clusters in the main window, it is possible to either include or exclude entire clusters of barcodes from downstream analysis. The image below illustrates the built-in AMLTutorial dataset. With the AMLStatus category selected and the 'Normal' cluster de-selected, as shown below:
The reclustering workflow will respond in kind, removing the Normal barcodes:
It is also possible to filter by custom categories, such as those created with the lasso tools, quantitative filters, boolean filters, or CSV import. It is recommended that these categories be created prior to initiating the reclustering workflow.
Finally, for finer-grained control, or to filter by lists defined by external algorithms, it is possible to either explicitly include or exclude a set of barcodes by clicking the Upload CSV link below the plot.
Threshold by UMIs
The next step is to threshold by UMI count. This step shows a violin plot of UMI counts of the currently selected barcodes. Moving the sliders at the top and bottom of the distribution will remove barcodes from outside the range. It is also possible to enter numerical values explicitly, or see the distribution on a log plot. For the purpose of this tutorial, an upper UMI count limit of 20,000 will be used, as shown below.
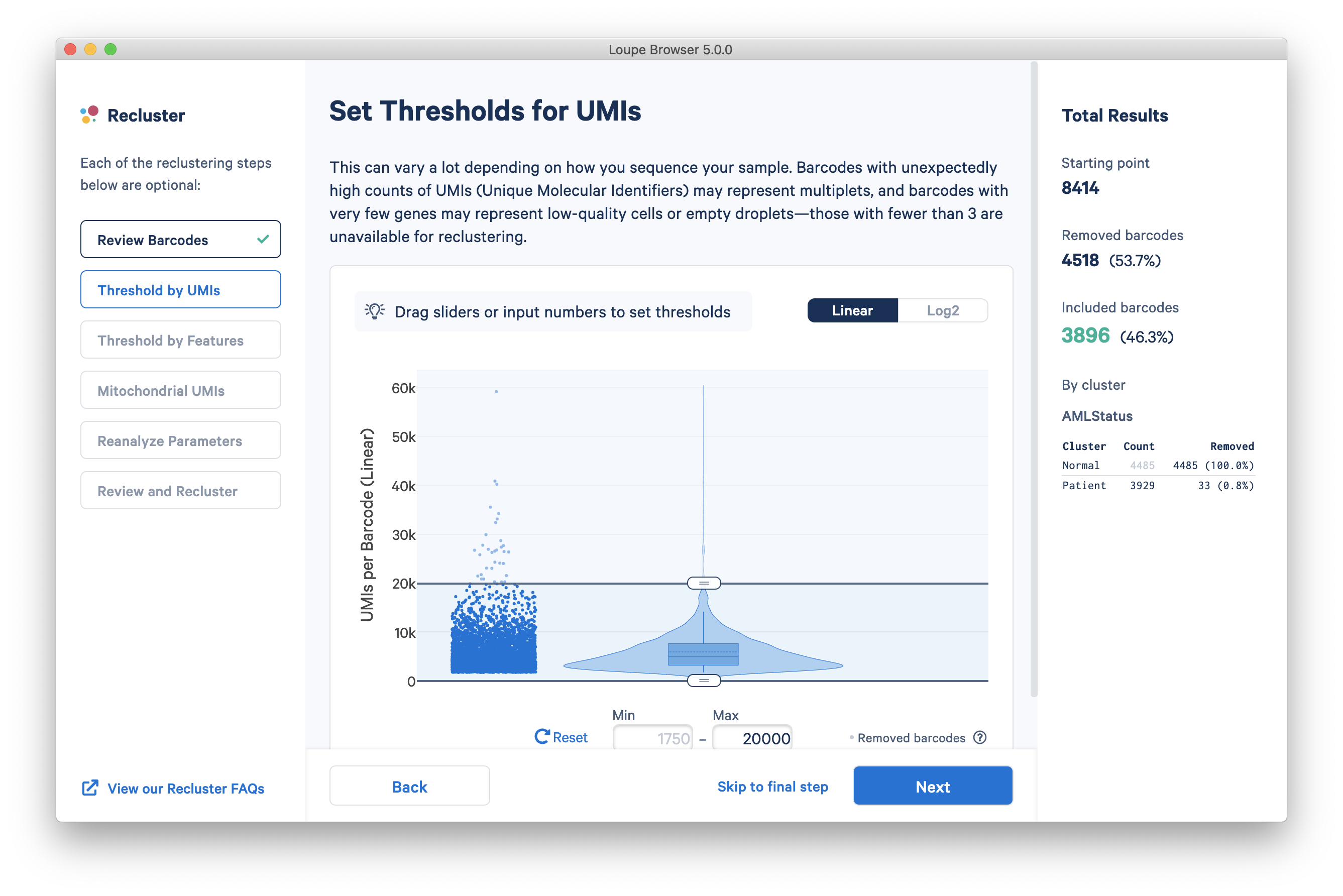
Threshold by Features
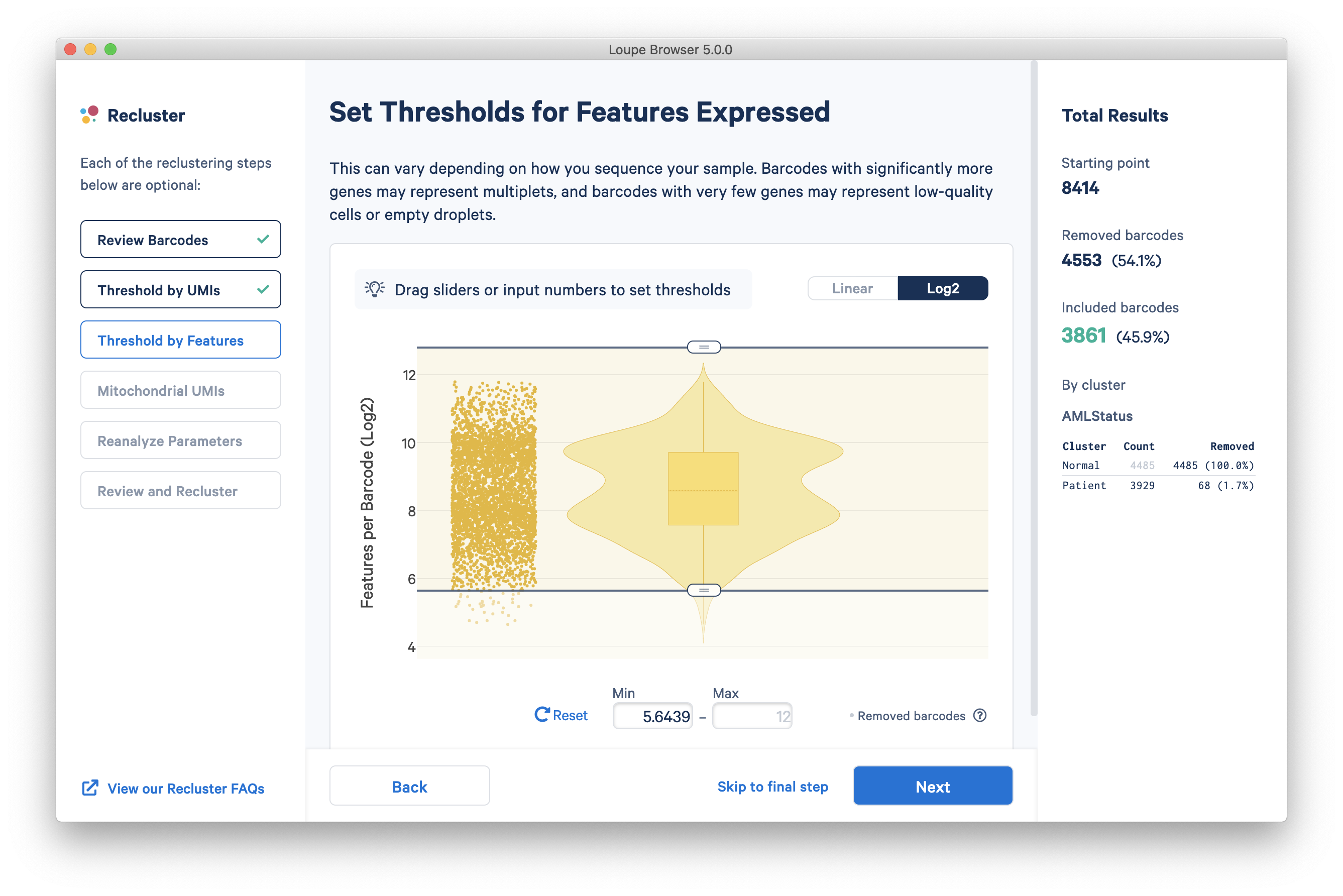
The next step is to threshold by distinct number of features detected. For gene expression datasets (even with feature barcoding), this will be the number of distinct genes found for each barcode. Depending on the experiment, barcodes with anomalously low or high numbers of distinct features may be undesirable. For the purpose of this tutorial, a lower feature count bound of 50 will be used, as shown below in log scale.
Mitochondrial UMIs
The next step is to filter cells by mitochondrial fraction -- the percentage of UMIs per barcode associated with mitochondrial genes. This step requires either the selection of a predefined reference (human or mouse), or uploading the set of mitochondrial genes for a custom reference. Clicking the 'Select a Reference Genome' dropdown will show the list of pre-recognized references, along with the percentage of mitochondrial genes in that reference which are present in the dataset. The AMLTutorial dataset is a human dataset, with most mitochondrial genes present.
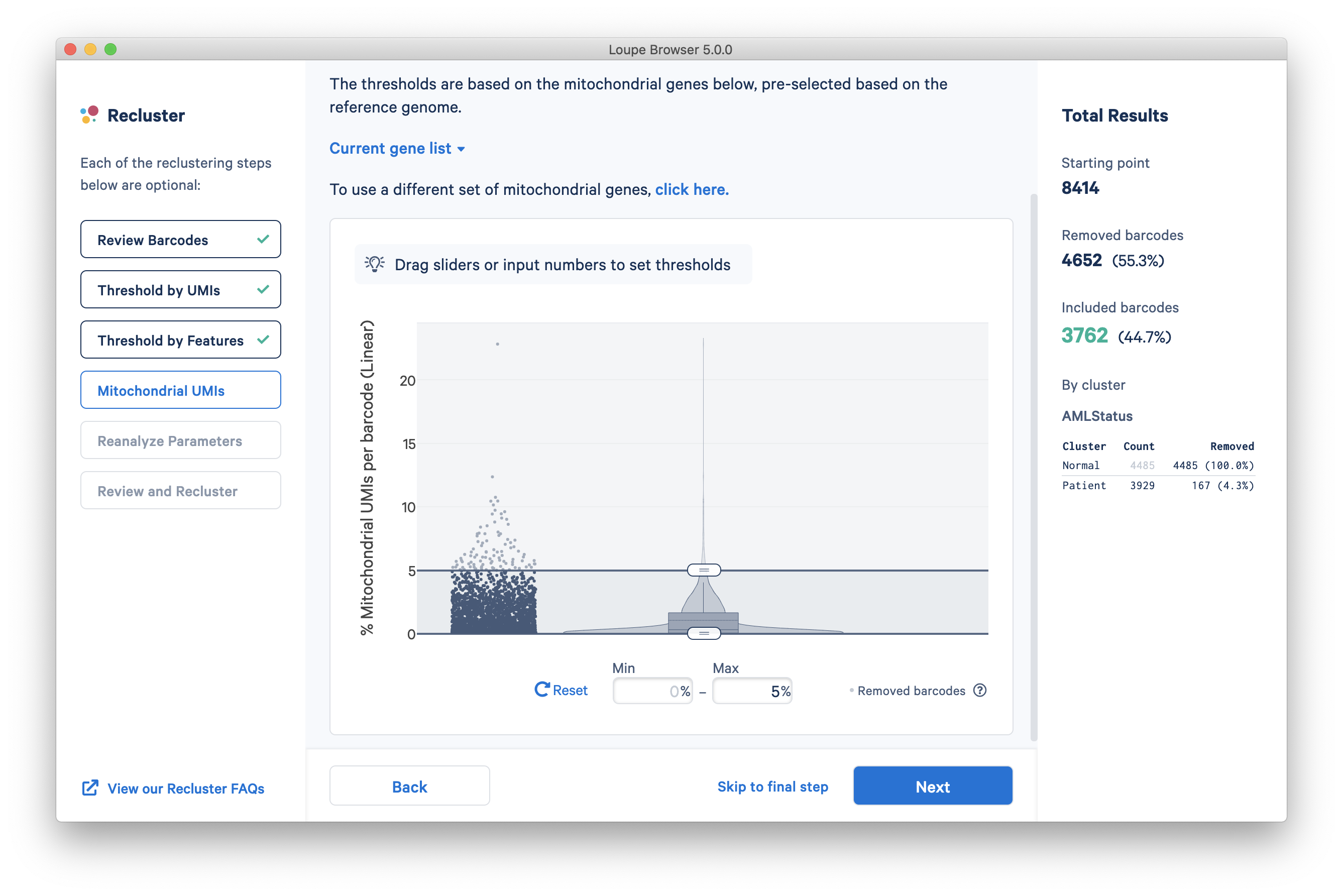
After selecting a reference or uploading a gene list, another violin plot and slider will be visible. For the purpose of this tutorial, a mitochondrial fraction upper bound of 5% will be used.
Reanalyze Parameters
With the filtering steps done, it is possible to enter custom parameters for either the dimensionality reduction used for clustering, or the parameters for generating the t-SNE plot. There are detailed instructions in this step; defaults are recommended, and no action is necessary if the default values are acceptable.
Review and Recluster
Finally, the last step is to review the statistics and name the filtered dataset. The name will be used in the main window as both the projection and clustering category, so it should be recognizable. In this tutorial, the name 'PatientOnly' is appropriate, given that the filtering limited the barcodes to the Patient subset, as well as applying some exclusion of high-UMI, low-feature and high-mito% barcodes.
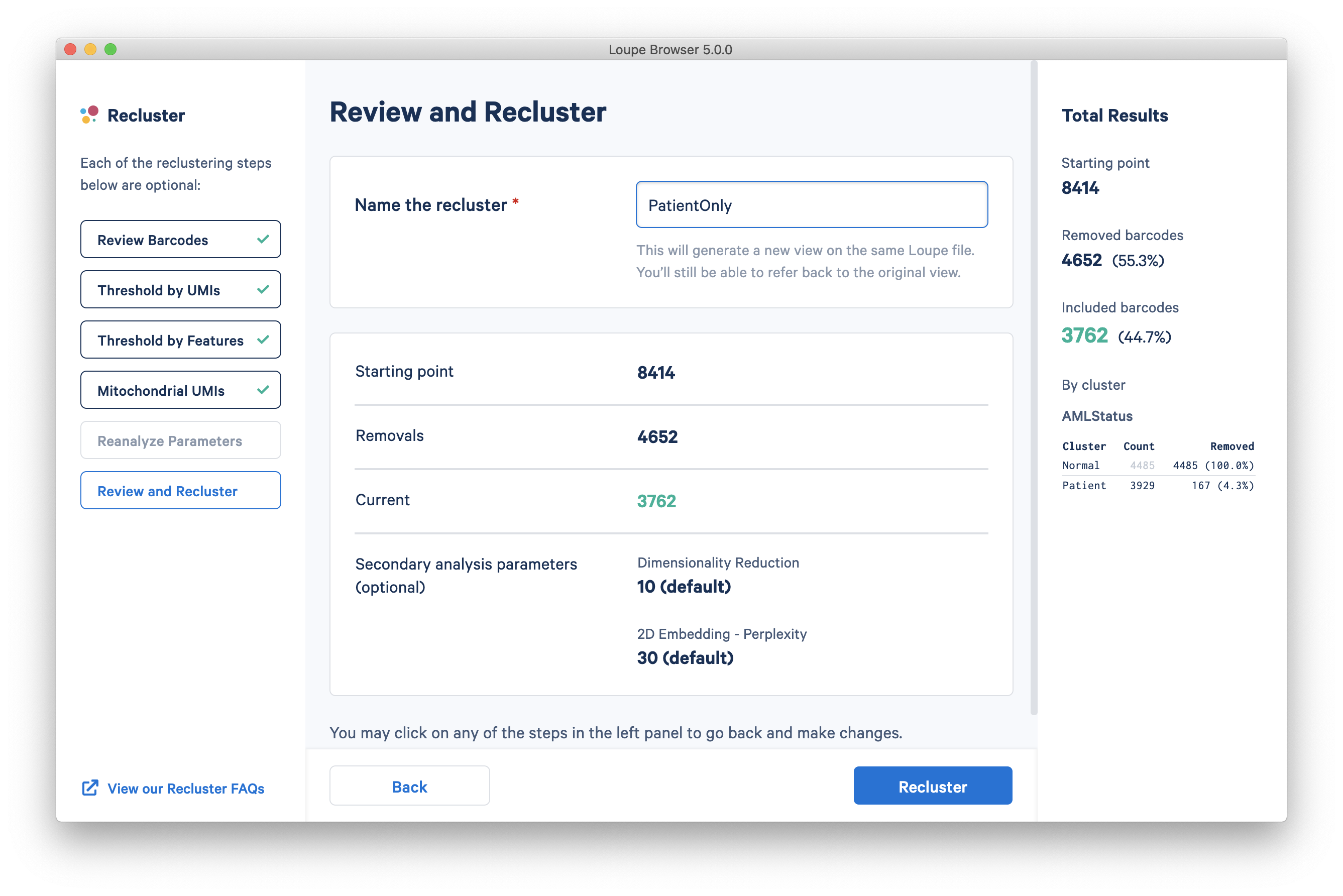
Pressing the Recluster button will then kick off the reclustering algorithms. In the background, Loupe will run virtually the same principal components, Louvain clustering, and t-SNE algorithms as the Cell Ranger pipeline.
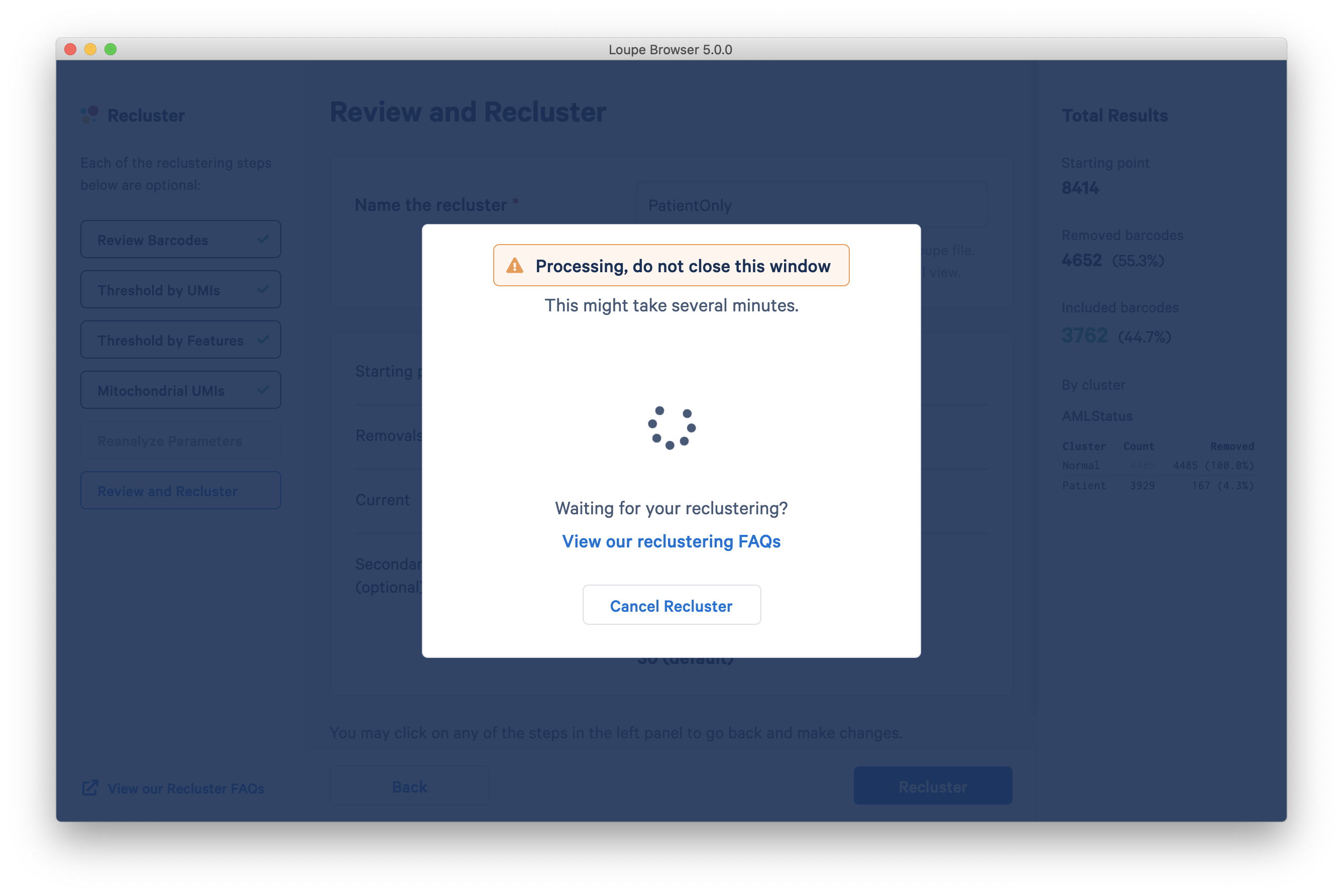
Run time will depend on your local machine speed, but is most dependent on the number of barcodes going into the reclustering. Expect most datasets under 10,000 cells to reprocess in less than two minutes. Higher datasets above 30,000 cells may take 10 minutes, and there is a hard cap at 100,000 cells. Datasets near that 100,000-cell limit may take nearly an hour to process.
Analyzing Reclustered Data
When reclustering completes, click on the Done button, which will close the workflow window, and bring up the new projection and category in the main window. The AMLTutorial PatientOnly dataset is shown below:
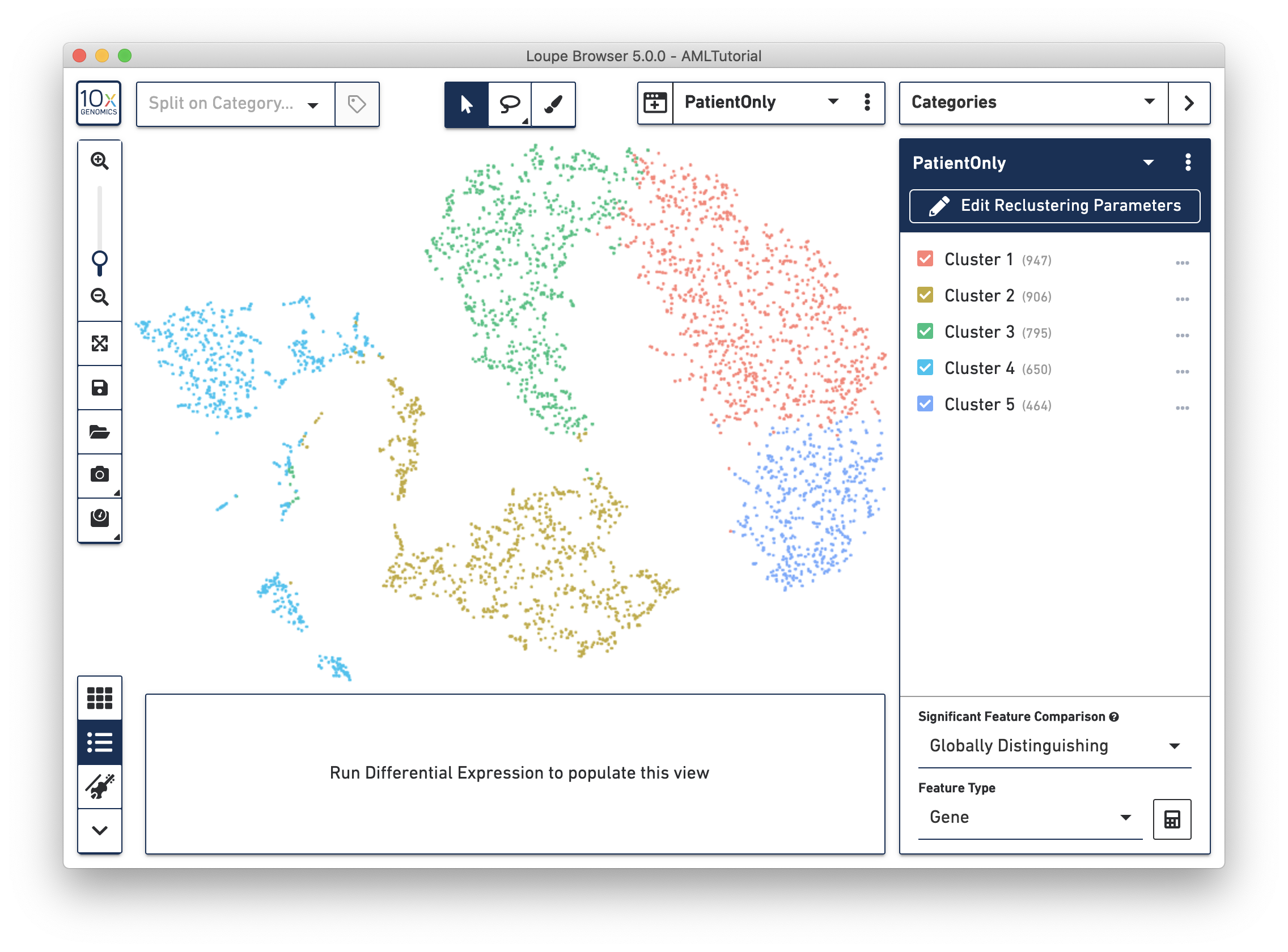
All operations in Loupe done while the reclustering-derived projection is visible will be limited to the barcodes in that projection. In that manner, it is possible to look up significant genes limited to the reclustered barcodes, see gene expression projections with that cell subset, as well as see clonotype lists limited to the active barcode set. In addition, selecting a category derived from a reclustering will automatically load the projection associated with that reclustering. However, it is still possible to change projections while a reclustering-derived category is active, to see how the recomputed clusters map onto the larger data.
Saving the .cloupe at this time will save the reclustered projections and categories only (though not any computed differential expression data). Finally, it is possible to either tweak the reclustering or recall its parameters by clicking on the 'Edit Reclustering Parameters' button, located below any reclustered category.
Reclustering FAQs
About & Specifications
-
Which 10x products can I filter and recluster?
- At this time, reclustering is available for Single Cell Gene Expression datasets. If you are analyzing a Single Cell Gene Expression dataset with Feature Barcode data, reclustering is possible, but the reclustering algorithm will only consider genes in the reanalysis, and not create new projections based on feature barcode analytes. Support for additional products is forthcoming.
-
How many cells can I recluster? Are there any limits?
- You can recluster a minimum of ten cells and a maximum of 100,000 cells. If your dataset is larger than 100,000 cells, you can make use of the cellranger reanalyze pipeline.
-
Does reclustering recompute the PCA?
- Yes, reclustering recomputes the PCA. You can also specify the exact number of principal components by entering a specific number into the field “2D Embedding - Input Principal Components” in the reclustering step “Reanalyze Parameters”.
-
What type of projection does reclustering generate (e.g. t-SNE, UMAP)?
- At this time, reclustering generates a t-SNE projection. UMAP support will be added in the future. If you would like us to support additional projections beyond t-SNE, give feedback to the team here.
-
How can I provide feedback or feature requests related to reclustering?
- Give feedback to the team here, or you can email our support exports at support@10xgenomics.com.
Troubleshooting
-
Why can I not see UMAP for my reanalysis?
- At this time, reclustering only generates t-SNE projections. UMAP support will be added in the future. If you have thoughts on this feature, you can give feedback here.
-
Why is reclustering taking so long?
- Do not be concerned if reclustering is taking a while. The speed of reclustering is dependent on your processing power and the size of your dataset. A 30k cell dataset may take around ten minutes or more. If reclustering is taking much longer than you expect, you can try restarting Loupe Browser and retrying the reclustering process.