10x Genomics
Visium Spatial Gene Expression
Space Ranger1.3, printed on 07/29/2025
Generating FASTQs with spaceranger mkfastq
Table of Contents
- Overview
- Example Workflows
- Arguments and Options
- Example Data
- Running mkfastq with a simple CSV samplesheet
- Running mkfastq with an Illumina Experiment Manager sample sheet
- Checking FASTQ output
- Troubleshooting
The Illumina NovaSeq control software v1.8 upgrade affects the ability of spaceranger mkfastq to autodetect the i5 (Index 2) orientation due to Illumina's reagent name changes in the recipe XML file. This results in all reads going into Undetermined and there will be no error. Several solutions to fix this issue are provided on this Knowledge Base article.
|
Overview
The spaceranger workflow starts by demultiplexing the Illumina sequencer's base call files (BCLs) for each flowcell directory into FASTQ files. 10x has developed spaceranger mkfastq, a pipeline that wraps Illumina's bcl2fastq and provides a number of convenient features in addition to the features of bcl2fastq:
- Translates 10x sample index names into the corresponding oligonucleotides in the i7/i5 dual-index. For example, well A1 can be specified in the samplesheet as SI-TT-A1, and spaceranger mkfastq will recognize the i7 and i5 indices as
GTAACATGCGandAGTGTTACCT, respectively. - Supports a simplified CSV samplesheet format to handle 10x use cases.
- Generates sequencing and 10x-specific quality control metrics, including barcode quality, accuracy, and diversity.
- Supports most
bcl2fastqarguments, such as--use-bases-mask.
Example Workflows
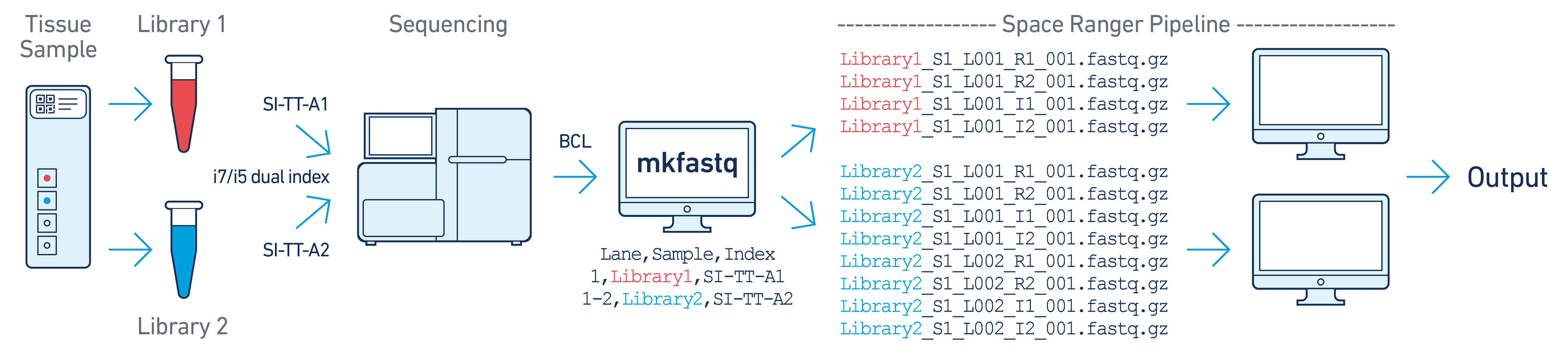
In this example, there are two 10x libraries (each processed through a separate capture area) that are multiplexed on a single flowcell. Note that after running spaceranger mkfastq, we run a separate instance of the pipeline on each library.
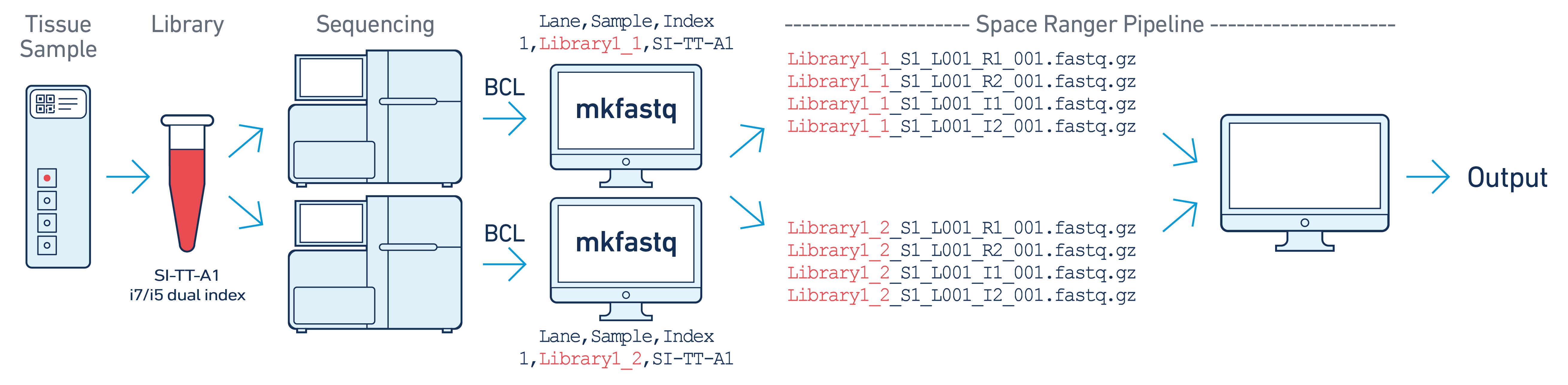
In this example, one 10x library is sequenced on two flowcells. Note that after running spaceranger mkfastq, we run a single instance of the pipeline on all the FASTQ files generated.
Arguments and Options
spaceranger mkfastq accepts additional options beyond those shown in the table below because it is a wrapper around bcl2fastq. Consult the User Guide for Illumina's bcl2fastq for more information.
| Parameter | Function |
|---|---|
| --run | (Required) The path of Illumina BCL run folder. |
| --id | (Optional; defaults to the name of the flowcell referred to by --run) Name of the folder created by mkfastq. |
| --samplesheet | (Optional) Path to an Illumina Experiment Manager-compatible sample sheet which contains 10x sample dual-index names (e.g., SI-TT-A12) in the sample index column. All other information, such as sample names and lanes, should be in the sample sheet. |
| --sample-sheet | (Optional) Equivalent to --samplesheet above. |
| --csv | (Optional) Path to a simple CSV with lane, sample, and index columns, which describe the way to demultiplex the flowcell. The index column should contain a 10x sample dual-index name (e.g., SI-TT-A12). This is an alternative to the Illumina IEM sample sheet, and will be ignored if --samplesheet is specified. |
| --simple-csv | (Optional) Equivalent to --csv above. |
| --filter-dual-index | (Optional) Only demultiplex samples identified by i7/i5 dual-indices (e.g., SI-TT-A6), ignoring single-index samples. Single-index samples will not be demultiplexed. Also notice that spaceranger will run single-index data, but it is not supported. |
| --lanes | (bcl2fastq option) Comma-delimited series of lanes to demultiplex (e.g. 1,3). Use this if you have a sample sheet for an entire flowcell but only want to generate a few lanes for further 10x analysis. |
| --use-bases-mask | (bcl2fastq option) Same meaning as for bcl2fastq. Use to clip extra bases off a read if you ran extra cycles for QC. |
| --delete-undetermined | (bcl2fastq option) Delete the Undetermined FASTQs generated by bcl2fastq. Useful if you are demultiplexing a small number of samples from a large flowcell. |
| --output-dir | (bcl2fastq option) Generate FASTQ output in a path of your own choosing, instead of flowcell_id/outs/fastq_path. |
| --project | (bcl2fastq option) Custom project name, to override the samplesheet or to use in conjunction with the --csv argument. |
| --jobmode | (Martian option) Job manager to use. Valid options: local (default), sge, lsf, or a .template file. |
| --localcores | (Martian option) Set max cores the pipeline may request at one time. Only applies when --jobmode=local. |
| --localmem | (Martian option) Set max GB the pipeline may request at one time. Only applies when --jobmode=local. |
Example Data
spaceranger mkfastq recognizes two file formats for describing samples: a simple, three-column CSV format, and the Illumina Experiment Manager (IEM) sample sheet format used by bcl2fastq. There is an example below for running mkfastq with each format.
The example (tiny-bcl) dataset is solely designed to demo the spaceranger mkfastq pipeline. It cannot be used to run downstream pipelines (e.g. spaceranger count).
To follow along, do the following:
- Download the tiny-bcl tar file.
- Untar the tiny-bcl tar file in a convenient location. This will create a new
tiny-bclsubdirectory. - Download the simple CSV layout file: spaceranger-tiny-bcl-simple-1.0.0.csv.
- Download the Illumina Experiment Manager sample sheet: spaceranger-tiny-bcl-samplesheet-1.0.0.csv.
Running mkfastq with a Simple CSV Samplesheet
A simple csv samplesheet is recommended for most sequencing experiments. The simple csv format has only three columns (Lane, Sample, Index), and is thus less prone to formatting errors. You can see an example of this in spaceranger-tiny-bcl-simple-1.0.0.csv:
Lane,Sample,Index 1,test_sample,SI-TT-D9
Here are the options for each column:
| Lane | Which lane(s) of the flowcell to process. Can be either a single lane, a range (e.g., 2-4) or '*' for all lanes in the flowcell. |
| Sample | The name of the sample. This name is the prefix to all the generated FASTQs, and corresponds to the --sample argument in all downstream 10x pipelines.Sample names must conform to the Illumina bcl2fastq naming requirements. Only letters, numbers, underscores and hyphens area allowed; no other symbols, including dots (".") are allowed. |
| Index | The 10x sample dual-index that was used in library construction, e.g., SI-TT-D9. |
To run mkfastq with a simple layout CSV, use the --csv argument.
Here's how to run mkfastq on the tiny-bcl sequencing run with the simple layout (replace code in red with the path to tiny_bcl on your system):
$ spaceranger mkfastq --id=tiny-bcl \ --run=/path/to/tiny_bcl\ --csv=spaceranger-tiny-bcl-simple-1.0.0.csv spaceranger mkfastq Copyright (c) 2019 10x Genomics, Inc. All rights reserved. ------------------------------------------------------------------------------- Martian Runtime - 1.3.1-4.0.5 Running preflight checks (please wait)... 2019-11-14 16:33:54 [runtime] (ready) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET 2019-11-14 16:33:57 [runtime] (split_complete) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET 2019-11-14 16:33:57 [runtime] (run:local) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET.fork0.chnk0.main 2019-11-14 16:34:00 [runtime] (chunks_complete) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET ...
Running mkfastq with an Illumina Experiment Manager Sample Sheet
The spaceranger mkfastq pipeline can also be run with a samplesheet in the Illumina Experiment Manager (IEM) format. If you didn't sequence with sample indices, you'll need to use this format. Briefly look at spaceranger-tiny-bcl-samplesheet-1.0.0.csv before running the pipeline. You
will see a number of fields specific to running on Illumina platforms, and then a [Data] section. That section is where you put your sample, lane and index information. Here's an example:
[Data] Lane,Sample_ID,Sample_Name,Sample_Plate,Sample_Well,I7_Index_ID,index,I5_Index_ID,index2,Sample_Project,Description 1,s1,test_sample,,,SI-TT-D9,SI-TT-D9,SI-TT-D9,SI-TT-D9,p1,
Here, SI-TT-D9 refers to a 10x sample dual-index.
In this example, only reads from lane 1 will be used. To demultiplex the given sample index across all lanes, omit the lanes column entirely.
Sample names must conform to the Illumina bcl2fastq naming requirements. Specifcally only letters, numbers, underscores and hyphens area allowed. No other symbols, including dots (.) are allowed.
Also note that while an authentic IEM sample sheet will contain other sections above the [Data] section, these are optional for demultiplexing. For demultiplexing an existing run with spaceranger mkfastq, only the [Data] section is required.
Next, run the spaceranger mkfastq pipeline, using the --samplesheet
argument (replace code in red with the path to tiny_bcl on your system):
$ spaceranger mkfastq --id=tiny-bcl \ --run=/path/to/tiny_bcl \ --samplesheet=spaceranger-tiny-bcl-samplesheet-1.0.0.csv spaceranger mkfastq Copyright (c) 2019 10x Genomics, Inc. All rights reserved. ------------------------------------------------------------------------------- Martian Runtime - 1.3.1-4.0.5 Running preflight checks (please wait)... 2019-11-14 16:35:49 [runtime] (ready) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET 2019-11-14 16:35:52 [runtime] (split_complete) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET 2019-11-14 16:35:52 [runtime] (run:local) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET.fork0.chnk0.main 2019-11-14 16:35:58 [runtime] (chunks_complete) ID.tiny-bcl.MAKE_FASTQS_CS.MAKE_FASTQS.PREPARE_SAMPLESHEET ...
If you encounter any preflight errors, refer to the Troubleshooting page.
Checking FASTQ Output
Once the spaceranger mkfastq pipeline has successfully completed, the output can be found in a new folder named with the value you provided to spaceranger mkfastq in the --id option (if not specified, defaults to the name of the flowcell):
$ ls -l drwxr-xr-x 4 jdoe jdoe 4096 Nov 14 12:05 tiny-bcl
The key output files can be found in outs/fastq_path, and are organized
in the same manner as a conventional bcl2fastq run:
$ ls -l tiny-bcl/outs/fastq_path/ drwxr-xr-x 3 jdoe jdoe 3 Nov 14 12:26 Reports drwxr-xr-x 2 jdoe jdoe 8 Nov 14 12:26 Stats drwxr-xr-x 3 jdoe jdoe 3 Nov 14 12:26 tiny-bcl -rw-r--r-- 1 jdoe jdoe 20615106 Nov 14 12:26 Undetermined_S0_L001_I1_001.fastq.gz -rw-r--r-- 1 jdoe jdoe 51499694 Nov 14 12:26 Undetermined_S0_L001_R1_001.fastq.gz -rw-r--r-- 1 jdoe jdoe 152692701 Nov 14 12:26 Undetermined_S0_L001_R2_001.fastq.gz $ tree tiny-bcl/outs/fastq_path/tiny_bcl/ tiny-bcl/outs/fastq_path/tiny_bcl/ Sample1 Sample1_S1_L001_I1_001.fastq.gz Sample1_S1_L001_R1_001.fastq.gz Sample1_S1_L001_R2_001.fastq.gz
This example was produced with a sample sheet that included "tiny-bcl" as the Sample_Project, so the directory containing the sample folders is named tiny-bcl. If a Sample_Project wasn't specified, or if a simple layout CSV file was used (which does not have a Sample_Project column), the directory containing the sample folders would be named according to the flow cell ID instead.
If you want to remove the Undetermined FASTQs from the output to save space, you can run mkfastq
with the --delete-undetermined flag. To see all spaceranger mkfastq options, run spaceranger mkfastq --help.
Troubleshooting
If you encounter a crash while running spaceranger mkfastq, upload the tarball (with the extension .mri.tgz) in your output directory:
spaceranger upload youremail@institution.edu jobid.mri.tgz
where jobid is what you input into the --id option of mkfastq (if not specified, defaults to the ID of the flowcell). This tarball contains numerous diagnostic logs that we can use for debugging.
You will receive an automated email from 10x Genomics. If not, email support@10xgenomics.com. For the fastest service, respond with the following:
- The exact command line you used.
- The sample sheet that you used.
- The RunInfo.xml and runParameters.xml files from your BCL directory.
- The kind of libraries you are demultiplexing (including chemistry).
- 1.0
- 1.1
- 1.2
- 2.0 (latest)
- Space Ranger v1.3